













КОРПОРАТИВНЫЕ СИСТЕМЫ
О подходах к интеграции данных о клиентах и повышению их качества написано уже немало, что, в частности, связано с наметившимся в последнее время интересом к CRM-решениям. Это и понятно: сложно говорить об управлении взаимоотношениями с клиентами, если невозможно с уверенностью сказать, кто они такие, как мы с ними работали раньше, каковы их потребности и какую ценность представляет каждый из них для компании.
CRM - это прежде всего информация о клиенте
Я не встречал ни одной организации, которая не сталкивалась бы с проблемой разрозненности и противоречивости сведений о клиентах и об истории взаимоотношений с ними. Причин, порождающих подобные проблемы, множество. Это и желание быстро и дешево решать текущие задачи в условиях отсутствия ИТ-стратегии, и участившиеся слияния и поглощения одних компаний другими при сохранении существующих у них ИТ-инфраструктур, и столкновение интересов топ-менеджеров. Не будем копаться в первопричинах, а воспримем текущую ситуацию как данность, как вызов, на который необходимо дать ответ - технологичный и эффективный с точки зрения затрат.
Конечно, внедрение CRM-решения помогает осознать важность получения целостного представления о каждом клиенте. Однако неправильно было бы рассматривать CRM как панацею, позволяющую раз и навсегда забыть о проблеме качества клиентской информации. Во-первых, чтобы пересчитать представленные на российском рынке комплексные CRM-системы, охватывающие все фронт-офисные процессы и каналы взаимодействия с клиентом, достаточно пальцев одной руки, а полномасштабных внедрений в нашей стране пока вообще нет. В реальной жизни нередко в call-центре используется одна база данных, для поддержки процесса сложных продаж - другая, в департаменте маркетинга - третья и т.д. Во-вторых, информация о клиенте накапливается не только в CRM-системах, но и в приложениях для управления заказами и финансами, относящихся к контуру ERP. Конечно, если организация использует интегрированную систему управления предприятием, объединяющую CRM- и ERP-компоненты в рамках единой информационной базы, то проблемы их интеграции просто не существует. Тем не менее таких организаций пока очень немного. Ну и наконец, следует помнить о появлении "клонов" одного и того же клиента в базе данных - зле, которое не обходит стороной и CRM. Более того, в силу особенностей ведения информации о клиентах эта проблема в CRM-приложениях стоит острее всего. Таким образом, я не вижу оснований выделять CRM-системы в том виде, в котором они используются большинством компаний, в особую безупречную касту - в контексте интеграции данных о клиентах они выступают на равных с другими типами приложений.
Определимся с понятиями
Такая характеристика, как качество данных, допускает довольно широкое толкование, а значит, для объективного сравнения различных подходов к повышению этого качества необходимо четко определить, что именно здесь имеется в виду. В нашем случае проблема качества информации о клиентах сводится к четырем факторам, сочетание и глубина проявления которых и определяют общий "масштаб бедствия":
- отсутствие синхронизации между списками (классификаторами) клиентов, ведущимися независимо друг от друга в нескольких информационных системах;
- фрагментация, т.е. наличие в каждом из используемых приложений только части информации, необходимой для полноценного анализа и принятия решений; это касается как атрибутов фирмы-клиента и ее контактных лиц, так и связанных с ними бизнес-объектов (маркетинговых кампаний, проведенных встреч, потенциальных сделок, заказов, оплат, обращений в службу поддержки и т.д.);
- противоречивость той части данных о клиентах, которая ведется параллельно в нескольких информационных системах. Противоречивыми могут оказаться как компоненты профиля клиента (точное название, форма собственности, адресные данные, контактная информация), так и компоненты бизнес-объектов (например, статус заказа, принимаемого в контуре CRM и обрабатываемого во внешней ERP-системе);
- дублирование клиентских записей внутри каждой прикладной системы (скажем, один и тот же заказчик фигурирует в разных записях под именами HP и Hewlett-Packard), которое приводит к проблемам, указанным в двух предыдущих пунктах, только в рамках одной базы данных; это не только не облегчает ситуацию, но даже усложняет ее, поскольку логика приложения и отчетность, как правило, изначально не учитывают возможное дублирование.
Перечисленные проблемы задают "систему координат", в которой должны сравниваться различные подходы к повышению качества данных о клиентах.
Известные способы решения проблемы
С разрозненностью и противоречивостью информации о клиентах организации борются давно, однако не всегда успешно. Используемые при этом методы, как правило, основаны на одном из двух принципов: либо на синхронизации информации между приложениями, либо на ее согласовании и консолидации в отдельной базе данных. Сегодня наиболее популярны три архитектуры, в той или иной мере позволяющие решать проблемы согласования и повышения качества данных:
- синхронизация по схеме "точка - точка";
- организация информационного хранилища;
- архитектура центрального узла обмена данными.
Остановимся на них подробнее.
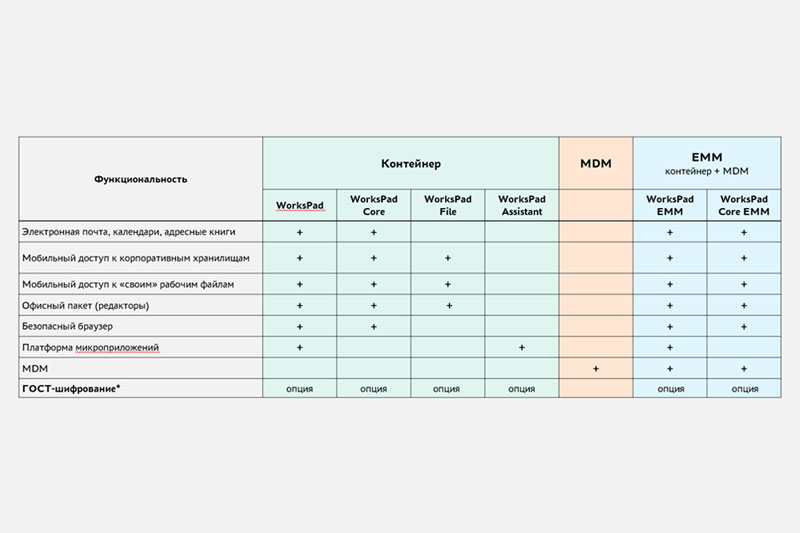
Синхронизация по схеме "точка - точка". Главными мотивами в пользу применения данного метода являются его простота и, как следствие, низкий уровень первоначальных инвестиций. В условиях традиционной "лоскутной" автоматизации задача практически всегда ставится локально: есть две базы данных, где хранится информация о клиентах, которую надо как-то синхронизировать. Тем не менее все резко усложняется, когда баз данных становится больше (см. рис. 1).
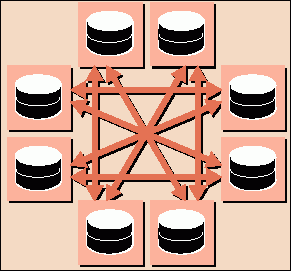
Рис. 1. При увеличении числа приложений, синхронизуемых
по схеме "точка - точка", задача существенно усложняется
О недостатках синхронизации по схеме "точка - точка" в сравнении с архитектурой центрального узла написано достаточно много, поэтому останавливаться на этом подробно не имеет смысла. Следует лишь отметить, что в рамках данной схемы действительно можно согласовать списки клиентов и устранить противоречия в информации, которая ведется одновременно в нескольких системах. При этом проблемы фрагментации и наличия в эксплуатируемых приложениях дубликатов клиентских записей остаются нерешенными.
Хранилище данных. Если основной целью интеграционного проекта является организация всестороннего анализа данных о клиентах, то, как правило, используется архитектура хранилища данных. Она предусматривает сбор соответствующей информации из всех приложений, ее очистку и размещение в специализированной базе данных, структура которой оптимизирована для генерации отчетов и аналитических процедур (см. рис. 2).
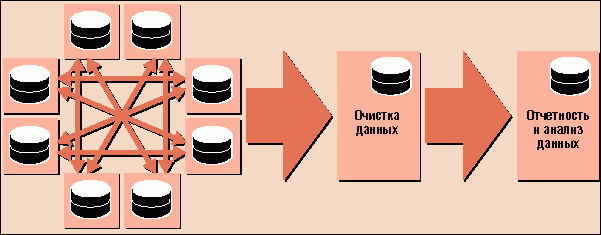
Рис. 2. При построении хранилища данных качество информации в исходных приложениях остается прежним
Может показаться, что с точки зрения вышеназванных критериев архитектура хранилища данных идеальна. Действительно, в ней решаются задачи создания единого классификатора клиентов, получения консолидированного представления обо всех связанных с ними операциях, устранения противоречий в информации из разных источников и дубликатов клиентских записей. Проблема состоит в том, что все это касается лишь непосредственно хранилища данных. Информация о клиентах перемещается только в одном направлении - из источников в хранилище, и процесс очистки никак не затрагивает транзакционные приложения. Таким образом, синхронизации данных между имеющимися на предприятии прикладными системами не происходит и основная причина всех проблем с качеством данных остается нерешенной.
Архитектура центрального узла обмена данными, являющаяся результатом усовершенствования модели синхронизации по схеме "точка - точка", обычно используется для синхронизации данных между приложениями, количество которых настолько велико, что попарная их интеграция становится слишком дорогой и сложной с точки зрения управления метаданными. Обмен информацией в этой схеме осуществляется не напрямую, а через центральный узел, представляющий собой репозиторий правил синхронизации и преобразования данных (см. рис. 3). Принципиальным отличием от архитектуры "точка - точка" является наличие обобщенной модели клиента и других бизнес-объектов в центральном узле. При этом форматы данных согласуются не между парами приложений, а между каждым из них и этой "обобщенной" моделью.
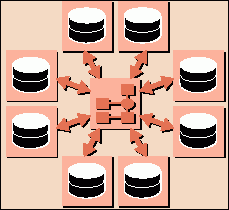
Рис. 3. В схеме с центральным узлом задачи
синхронизации решаются гораздо проще
Если вспомнить вышеупомянутые критерии, то архитектура узла обмена данными хорошо подходит для синхронизации справочников клиентов и связанных с ними транзакций, что помогает не допускать противоречий между данными из разных приложений. Если решения требуют именно эти задачи, и только они, то на такой модели можно и остановиться - что, собственно, многие и делают. С другой стороны, указанный подход тоже не лишен недостатков. Информация о клиенте по-прежнему остается фрагментированной, и для ее консолидации и полноценного анализа все равно необходимо развертывание хранилища данных. Кроме того, здесь не решается проблема дубликатов клиентских записей, и в результате мы имеем ситуацию, когда неполные данные о клиентах в одном приложении синхронизируются с некоторыми экземплярами подобных записей в другом. С этим злом приходится бороться индивидуально в каждой из имеющихся на предприятии прикладных систем.
Детальный анализ преимуществ и недостатков рассмотренных архитектур наводит на мысль о возможности построения гибридной схемы, сочетающей в себе лучшие черты различных подходов к синхронизации данных.
Архитектура центра данных о клиентах
Идея, на которой основано решение Oracle Customer Data Hub, проста и в то же время эффективна. Объединив возможность обмена данными через центральный узел со средствами получения консолидированной информации, мы получим архитектуру центра данных о клиентах. Ее главное отличие от схемы узла обмена данными - наличие в центральном узле не "виртуального" набора правил синхронизации и преобразования форматов, а реальной БД о клиентах.
Обмен данными между системами происходит в два этапа: вначале информация попадает из приложения-источника в центральную БД, где при необходимости может происходить ее выверка (в том числе контроль дублирования). Затем она передается в приложения-получатели, которые на эту информацию "подписаны". Тем самым архитектура центра клиентских данных принципиально отличается и от хранилища данных, так как в ней реализован двунаправленный поток информации - от транзакционных приложений в центральную базу и обратно (см. рис. 4).
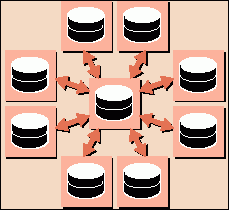
Рис. 4. В центральном узле Oracle Customer Data Hub
поддерживается реальная БД о клиентах
Как нетрудно увидеть, в рамках полученной архитектуры решаются все ключевые проблемы обеспечения качества данных:
- централизованно ведется главный классификатор клиентов, и изменение, появившееся в списке клиентов в любом из приложений, вначале вызовет соответствующую модификацию в главном классификаторе, а затем будет передано в остальные приложения;
- поддерживаемая в главном узле модель данных о клиенте и связанных с ним бизнес-объектах позволяет впоследствии анализировать все аспекты взаимодействия компании с клиентами, хотя информация о них по-прежнему накапливается независимо в каждом приложении;
- центральная БД является естественным "единым источником правды" о клиенте; противоречия в информации, поддерживаемой различными приложениями, выявляются и разрешаются централизованно, при этом данные могут быть сверены в любой момент;
- задача идентификации и устранения дублированных записей также централизуется, благодаря чему снижается трудоемкость ее решения: вместо того чтобы устранять дубликаты в каждом приложении отдельно, можно создать единый алгоритм, запустить его выполнение на центральной БД и затем передавать информацию о наличии "клонов" обратно в исходные приложения.
Среди дополнительных преимуществ архитектуры центра данных о клиентах - возможность использования универсального "визуализатора" информации, централизованная верификация и обогащение данных на основе справочных баз внешних поставщиков (таких, как Dun & Bradstreet и Trillium), а также, если в этом есть необходимость, централизация и стандартизация процедур создания новых клиентов и внесения изменений в данные об уже существующих.
Конечно же за все приходится платить. В данном случае имеет место дублирование информации о клиентах, что, в частности, влечет дополнительные расходы на аппаратные средства.
Каждый выбирает свой путь
Вообще говоря, выбор архитектуры интеграции данных о клиентах - вопрос, не имеющий универсального ответа. В каждом конкретном случае оптимальный подход определяется целями (что именно организация хочет получить от интеграции) и существующими ограничениями (в основном спецификой приложений, в которых фиксируются данные о клиентах). Естественно, каждый производитель программного обеспечения подчеркивает преимущества своего решения. Так, SAS Institute пропагандирует идеологию хранилища данных как необходимой основы CRM-системы; компании SAP и Siebel придерживаются подхода, используемого в архитектуре узла обмена данными (продукты SAP Master Data Management и Siebel Universal Application Network); Oracle, также имея в своем арсенале технологию Application InterConnect для схемы узла обмена данными, в новом продукте Customer Data Hub реализовала архитектуру центра данных о клиентах.
Если оставить за скобками хранилище данных, предназначенное все же для решения специфических задач анализа, то основными факторами, влияющими на выбор между узлом обмена данными и центром данных о клиентах, являются количество эксплуатируемых приложений и требования к качеству информации в каждом из них. Если прикладных систем немного, а проблема дублирования клиентских записей не является критичной, то, скорее всего, будет хорошо работать схема узла обмена данными. Однако с увеличением числа приложений растут сложность управления метаданными и трудоемкость устранения дубликатов: для этого придется создавать уникальные для каждой информационной системы процедуры. В подобных условиях оптимальным представляется подход, примененный в архитектуре центра данных о клиентах. Дополнительный фактор, который может склонить чашу весов в сторону этой архитектуры, - необходимость получения консолидированного представления обо всей истории работы с клиентом, что гораздо проще реализовать с помощью центра данных о клиентах.
Безусловно, предлагаемый критерий весьма субъективен. Что значит "большое количество" приложений - вопрос, который каждая организация для себя решает сама исходя из специфики своей информационной инфраструктуры. Можно лишь констатировать, что сегодня на рынке существуют решения, помогающие на приемлемом уровне реализовать любой из описанных выше подходов. Похоже, что миссия получения качественной информации о клиентах сегодня действительно выполнима...
С автором, Романом Самохваловым, можно связаться по адресу: Roman.Samokhvalov @oracle.com.







