














Одним из наиболее ожидаемых событий суперкомпьютерной конференции SC’15 в Остине (США) была публикация очередного,
Недостаточную объективность TOP500 в приложении к современным реалиям признали даже его создатели. Два года назад авторский коллектив теста LINPACK во главе с профессором Университета Теннесси Джеком Донгарра предложил новый тест для определения производительности суперкомпьютеров — High Performance Conjugate Gradient (HPCG).
Сам Донгарра в пояснительной записке к последней редакции теста определил роль HPCG как «дополнение к традиционному бенчмарку LINPACK (HPL)». Для тех, кто принимает окончательное решение о финансировании таких дорогих многолетних проектов, коими являются суперкомпьютеры, вопрос оценки производительности — далеко не пустой звук, поскольку эффективность инвестиций в любом случае приходится оценивать тем или иным способом. Не говоря уж о престиже страны, системы которой занимают строчки в общепризнанном авторитетном международном рейтинге.
Основанный на HPCG рейтинг значительно отличается от того, что мы видим в классическом TOP500, однако полную картину рынка всё же пока даёт только он.
Классический TOP500 (LINPACK): верхи не хотят, низы не могут
Изменения в
Гораздо сильнее изменения на региональном уровне. Лидером обновлений является Китай, практически утроивший число систем в последнем списке TOP500, и, что не менее важно, представленный большим числом местных производителей HPC. Число суперкомпьютеров, инсталлированных в США, напротив, снизилось до 200 (в предыдущем июльском
Число европейских систем в списке снизилось за полгода со 141 до 108, зато системы азиатского региона сделали за то же время гигантский скачок со 107 до 173 систем, при этом 109 из них работают в Китае (полгода назад в списке было только 37 китайских систем). В некоторой степени такой расклад объясняется усилением позиций Lenovo, поглотившей недавно серверный x86-бизнес IBM, но лишь отчасти, поскольку в TOP500 сейчас насчитывается 25 систем производства Lenovo (всего три в предыдущем списке), в то время как другой китайский производитель, компания Sugon, является производителем 49 систем последнего листинга, что превышает как собственно рейтинг IBM, снизившийся за полгода с 23 до 14,9%, так и число двухбрендовых позиций: IBM/Lenovo (девять систем) и Lenovo/IBM (пять систем). Первое место среди вендоров с долей 31,2% по-прежнему занимает HP (155 систем против 178 в прошлом рейтинге), второе место с долей 13,8% занимает Cray с неизменными 69 системами.
В последнем рейтинге TOP500 насчитывается уже 80 систем с производительностью более 1 Пфлопс, хотя в предыдущем рейтинге их было только 67. Суммарная производительность входящих в последний рейтинг систем составила 420 Пфлопс (361 Пфлопс в
В последний рейтинг вошли 104 системы с сопроцессорными и ускорительными технологиями, полгода назад в предыдущем TOP500 их насчитывалось всего 90. Первый (Tianhe-2) и последний (Stampede) суперкомпьютеры первой десятки рейтинга используют для ускорения вычислений сопроцессоры Intel Xeon Phi, второй (Titan) и седьмой (Piz Daint) оснащены графическими акселераторами Nvidia. Четыре системы из нового рейтинга включают как чипы Intel Xeon Phi, так и GPU-ускорители Nvidia, 66 систем выполнены с применением акселераторов Nvidia, три на акселераторах ATI Radeon, 27 на сопроцессорах Intel Xeon Phi.
Из пяти сотен систем 445 (89%) выполнены на процессорах Intel (86,2% в прошлом рейтинге), при этом чипы IBM Power используются только в 26 системах (38 систем в прошлом рейтинге), а чипы AMD Opteron в 21 системе (4,2%, в прошлом рейтинге — 4,4%). В сумме 86% систем выполнены на процессорах с числом ядер шесть и более, 88% — на восьми- и более ядерных процессорах, 47% на чипах с десятью и более ядрами. Технология InfiniBand по-прежнему остаётся наиболее популярным способом внутрисистемных коммуникаций, хотя её распространённость заметно упала: с 257 систем в прошлом рейтинге до 235 в новом. Напротив, распространённость Gigabit Ethernet выросла со 147 систем до 182, при этом в подавляющем числе случаев — 120 — речь идёт об интерфейсах 10G.
За полгода, прошедшие с момента подведения итогов
На сегодняшний день в TOP500 осталось семь российских систем (полгода назад их было восемь), а самый производительный российский суперкомпьютер «Ломоносов-2» («Т-Платформы») продолжает терять позиции, переместившись с
Если рассматривать TOP500 по вхождению в него систем российских вендоров, здесь можно отметить появление на
Рейтинг HPCG: дополнение вместо противопоставления
Ключевая критика, поступавшая в последние годы в адрес теста LINPACK (HPL), сводится, главным образом, к слишком простым алгоритмам расчётов, не способным равномерно нагрузить систему и все её ключевые компоненты для выявления узких мест вроде подсистемы памяти, или возможности проведения сложных расчётов.
Разъяснить ключевые отличия между бенчмарками HPL и HPCG помог Алексей Шмелев: «Дело в том, что LINPACK выстроен, главным образом, на решении систем линейных алгебраических уравнений методом LU-разложения. Тест HPCG, в свою очередь, использует как матрично-векторные операции умножения в разряжённых матрицах и векторные операции, так и решение систем линейных алгебраических уравнений методом сопряженных градиентов. Проще говоря, математический аппарат LINPACK скорее типичен для систем 10-20- летней давности, в то время как HPCG отражает математические методы, используемые современными высокомасштабируемыми приложениями. Таким образом, HPCG отражает эффективность при работе с реальными приложениями и выполнении актуальных задач научно-образовательными и научно-исследовательскими организациями».
В июне 2014 г. на конференции SC’14 был опубликован первый рейтинг на базе HPCG, тогда в него вошло всего 15 систем из традиционного рейтинга TOP500, год назад, на SC’14, список включал уже 25 систем.
В четвёртый по счёту рейтинг HPCG, представленный в рамках SC’15, вошло 64 системы из разных стран мира, большинство из которых представляют самую «верхушку» классического рейтинга. Это, конечно, ещё не TOP500, но уже вполне серьёзная заявка в качестве нового авторитетного и независимого рейтинга для оценки возможностей современных систем класса HPC. Отрадно отметить, что семь пунктов HPCG представлены суперкомпьютерами из России.
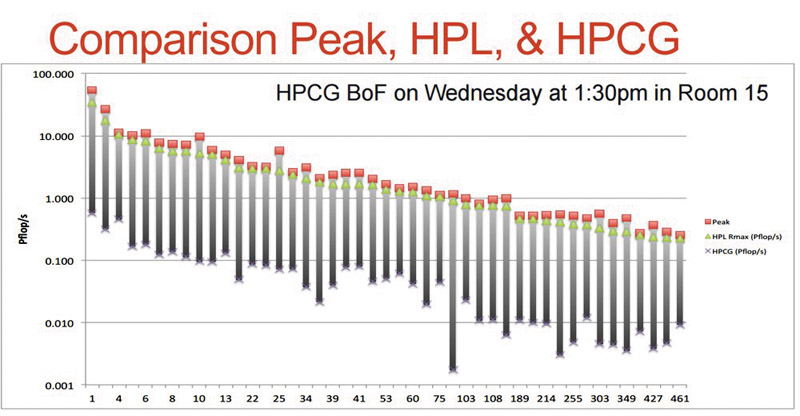
Список систем, ранжированных по тесту HPCG, в большинстве случаев значительным образом отличается от того порядка, в котором они присутствуют в классическом TOP500. Если сравнить абсолютные величины, разница получается просто огромная. Так, лидер обоих рейтингов китайский суперкомпьютер Tianhe-2 под LINPACK показывает производительность 33,863 Пфлопс, в то время как результат теста HPCG составляет 0,58 Пфлопс. Однако ещё более красноречивым инструментом сравнения этих бенчмарков, отражающего производительность систем под различной нагрузкой, является соотношение результатов, полученных в HPCG и HPL, соответственно. У выше упомянутого лидера оно составляет 1,7%, в то время как у занимающего вторую строчку японского суперкомпьютера K института RIKEN он составляет 4,4%.
Комментируя результаты четвёртого рейтинга HPCG, Джек Донгарра отмечает ряд достаточно интересных с точки зрения дальнейших перспектив бенчмарка наблюдений. В листинге наконец-то начали появляться системы класса IBM BlueGene, а суммарное число присутствующих в рейтинге российских систем сравнялось с числом суперкомпьютеров в рейтинге TOP500. Среди пополнений листинга HPCG также присутствуют такие новички TOP500, как выполненная на процессорах Haswell система Trinity департамента энергетики США, занимающая
HPL vs HPCG: дальнейшие перспективы
Даже поверхностный анализ результатов измерения с помощью нового берчмарка HPCG позволяет убедиться в том, что этот тест значительно более чутко реагирует на изменения производительности вычислительных систем, связанные с изменением их архитектуры или топологии. Так, например, кластерной платформе TSUBAME KFC на процессорах Intel Xeon E5-2620 v2 понадобилось всего лишь заменить графические ускорители Nvidia K20x на K80, чтобы практически удвоить производительность в последнем рейтинге HPCG. Классический LINPACK реагирует на такие изменения в гораздо меньшей степени.
Особенностью только что прошедшей конференции SC’15 можно назвать тот факт, что несмотря на ряд громких анонсов новых многообещающих технологий, их практическое использование в массовых системах мы увидим только в следующем году. Такие интересные решения, как графические акселераторы Nvidia Tesla M40 и Tesla M4, процессоры Intel Xeon Phi нового поколения с кодовым названием Knights Landing, элементы новой коммутационной технологии Intel Omni-Path Architecture, новые интеллектуальные EDR Infiniband-решения Mellanox Switch-IB 2 и ConnectX-4 Lx, подсистемы памяти на базе DDR4 и системы хранения данных на новых поколениях SSD — всё это и многое другое придаст значительный импульс в развитии новых поколений HPC.
Каждая из этих технологий значительным образом влияет на производительность современной вычислительной системы, но учесть всё это разнонаправленное влияние в ключе особенностей современных приложений старый добрый LINPACK, ядро которого написано более 20 лет тому назад, уже не в состоянии. Не исключено, что буквально через несколько итераций популярность нового бенчмарка HPCG перерастёт старый HPL, и уже в ближайшие годы станет основой для TOP500, составленного на основе более справедливых и объективных оценок.












