


Мировой рынок больших данных стабильно растет. Данные создаются лавинообразными темпами. Стремительно приближается время Интернета вещей, когда трафик, сгенерированный машинами, превысит интернет-трафик, сгенерированный людьми. Стали уже повседневностью облачные вычисления, о перспективах которых так много рассуждали всего лишь несколько лет назад. Мир стремительно дигитализируется, цифровые технологии проникают во все сферы нашей жизни.
Специалисты по-разному оценивают происходящие изменения. Одни говорят о новой, теперь уже четвертой промышленной революции и переходе к Индустрии 4.0. Другие, что если отбросить шум маркетологов, то в сухом остатке останется все та же старая, хорошо известная АСУ ТП, и речь просто идет об ее эволюции.
Новое — хорошо забытое старое
Перенесемся на 30 лет назад. Советский Союз. Маленький городок в Сибири. Сердце ядерного реактора — активная зона и настил над ее ячейками, называемый «пятак». Я, молодой аспирант МИФИ, первый раз стою на «пятаке», который гудит и вибрирует под ногами как живой. Триумф Советской науки, высшие достижения прогресса.
Неожиданно на пятак выходит группа мужиков с сильно помятыми лицами и начинают какими-то ломами долбить по ячейкам ядерного реактора, чтобы открыть каналы и провести измерения параметров. Возникает ощущение, что они ремонтируют трамвайные пути или открывают люки городской канализации. И восторг от достижений немного стихает.
Перемещаюсь в вычислительный центр. Огромный зал, в котором стоят машины ЕС-1045. Тогда я еще не знал, что это называется мейнфрейм на IBM. Девочки-операционистки, которые по моим заявкам входят в этот огромный, изолированный от внешнего мира отсек с постоянной температурой. Они ставят мне магнитные ленты с данными, ввозят на тележках огромные тяжелые жесткие диски и вручную их монтируют, с трудом ставя в специальные отсеки.
Я сижу в дисплейном классе и мучительно копаюсь в собранных данных о состоянии реактора, пытаясь найти еще не найденные закономерности. Используя методы регрессионного, факторного, кластерного анализа и только что появившиеся пакеты по матстатистике.
Все было страшно медленно, катастрофически не хватало вычислительных мощностей и данных, спал по три часа в сутки, но в итоге результат получил — выявил аномалию, которая могла привести к разрыву первого контура и серьезной аварии. После недавно случившегося Чернобыля к полученным результатам отнеслись достаточно серьезно, и это был еще один довод, приведший к решению о закрытии реактора.
Говоря современными словами, я занимался типичной Data Science. Мужиков с ломами можно рассматривать как элемент системы сбора данных Интернета вещей. Место вычислительного центра заняло облако. Вместо каталога файлов, куда подгружалась информация о содержимом монтируемого девушками диска, появился сервер имён (NameNode). Данные теперь не находятся в области данных на диске, а разбросаны по серверам данных (DataNode). Этакая огромная файловая система, которая теперь называется— HDFS (Hadoop Distributed File System). Файл с данными стал таким большим, что тоже разбросан по набору рабочих машин, на каждой из которых одновременно крутится сервер данных (DataNode) и воркер (TaskTracker). Появились средства управления этими распределенными машинами с данными, позволяющие распараллеливать задачи и самое главное производить вычисления над данными на тех машинах, где они расположены (MapReduce, Spark). То есть появились технологии больших данных. Но все же на первый взгляд принципиальных отличий не так много.
Переход количества в качество
Тем не менее, серьезные отличия есть. Произошел хорошо описанный Гегелем в философии переход количества в качество. Собираемых данных стало очень много, в том числе из-за значительного снижения стоимости датчиков. Резко упала стоимость хранения данных. В соответствии с законом Мура устойчиво продолжается увеличение мощности компьютеров при снижении их стоимости. Вычислительные мощности, которые обходились в 1955 г. в 10 долл., в
В результате стало возможным достаточно дешево собирать и хранить огромные объемы информации и перейти на новый уровень детализации при ее обработке. Раньше данные, зачастую собираемые вручную, были дорогими. Их было мало, и оценки проводились по выборке из группы. Именно так я анализировал данные о реакторе.
Другой пример использования — страховые компании. Если я выезжал за рубеж в обычную поездку, то с меня брали одну сумму. Если я указывал, что буду заниматься альпинизмом, то сумму в три раза большую. Вполне логично — переход в группу с большим риском — больше плата. Рентабельность страховых компаний возрастала с ростом объема клиентов. Прибыль с большинства клиентов небольшая, поэтому чем больше было застрахованных, тем лучше.
Переход к анализу больших данных дает возможность значительно повысить точность оценки риска, например, в моем случае — точно оценить уровень здоровья, альпинистский опыт, склонность к риску на восхождениях. У нас это еще дело будущего. Но за рубежом это уже используется.
Так, использование технологий больших данных позволило американским страховым компаниям перейти от вероятностной оценки групп к оценке конкретных лиц. Стало экономически эффективным рассчитывать вероятные результаты о здоровье на индивидуальной основе и отказывать людям со слабым здоровьем. В США бизнес-модель медицинского страхования перешла от охвата максимального количества людей к минимальному количеству и продаже страховки только здоровым людям, тем, кто не нуждается в здравоохранении.
Не будем рассматривать социальный аспект, возникшие связанные с этим проблемы и реформу Obamacare, но в плане бизнеса все стало отлично и прибыли страховых компаний стремительно увеличились. Так переход количества в качество привел к полной смене бизнес-модели. Причем не важно, где используются технологии больших данных. Вместо людей можно взять станки или элементы промышленных систем. Главное в новом подходе, основанном не на вероятностной оценке состояния групп, а конкретных единиц.
Успехи искусственного интеллекта
Другой эффект действия закона Мура — вернувшийся интерес с самообучающимся системам и системам с искусственным интеллектом (ИИ). Интерес к этим системам был давно. Темой активно занимались еще в
Все изменилось в самое последнее время. Стремительно возросшие вычислительные мощности привели к тому, что многие задачи стало возможным решать простым перебором. Так, например, IBM Watsom побеждает в американской игре Jeopardy!, которая у нас называется «Своя игра». Большой прогресс достигнут в области самообучающихся систем. Программа AlphaGo, разработанная компанией Google DeepMind, выиграла в игру Го у профессионала высшего дана. При этом она использовала недавние успехи в области машинного обучения, а именно глубинное обучение (Deep Learning) с помощью многоуровневых нейронных сетей.
CEO Microsoft Сатья Наделла заявил, что Azure движется по пути превращения в первый суперкомпьютер с искусственным интеллектом. Во всех регионах каждый вычислительный узел Azure имеет FPGA (программируемые вентильные матрицы логических элементов), и благодаря этому разработчики могут писать код нейросети, распространять его по инфраструктуре FPGA «и исполнять его с быстродействием полупроводниковых микросхем».
Amazon Web Services (AWS) в конце сентября представила обновление поддерживаемого с помощью GPU облачного сервиса, ориентированного на задачи искусственного интеллекта, сейсмического анализа, молекулярного моделирования, геномики и другие приложения, нуждающиеся в огромных объемах ресурсов для параллельных вычислений.
Развитие технологий, которые объединяют под зонтичным термином Big Data, делает реальным интеграцию киберфизических систем в заводские процессы. Причем сети машин могут не только производить товары с меньшим количеством ошибок, но и автономно изменять производственные шаблоны, подстраиваясь под каждого конкретного заказчика.
В России работы по созданию систем с ИИ тоже ведутся, например, в областях медицины и финансов, прежде всего в банковской сфере. Эксперты признают, что за ними будущее. Причем близкое. Как сказал Герман Греф, «через пять лет 80% решений в Сбербанке можно будет принимать с помощью искусственного интеллекта».
Облачные платформы начинают предоставлять услуги по IoT, большим данным и ИИ как сервис. Технологии активно выходят в массы. В России скоро состоится хакатон по созданию искусственного интеллекта для финансовых организаций, в рамках которого студенты за сутки должны создать работающие прототипы ИИ в совет директоров банка (системы принятия решений), ИИ-советник для трейдинга и управления инвестициями, ИИ для скоринга (оценки кредитоспособности физлиц). Не на пустом месте, а используя готовые API и SDK таких компаний, как Microsoft, Nvidia и Mail.ru. То есть задачи по созданию ИИ — это уже не только долгоиграющие проекты крупных компаний и академических вузов. Это уже задания для соревнований студентов.
Немного о моделях
Еще одно отличие от
Теперь же это часто не требуется. Исследования магнитно-резонансных томограмм (МРТ), изображений живых мозгов осужденных преступников показали, что без какой-либо базовой теории самообучающаяся система с вероятностью более 90% различала МРТ-снимки уголовников, которые способны на повторное преступление и которые не способны. Можно ли на основании МРТ принимать решение об условно-досрочном освобождении?
В юриспруденции такой подход пока не используется, а вот в финансах и промышленности уже. Машины самообучаются и часто дают результат, которому нет объяснения. Тем не менее, на основании этих результатов принимаются решения, причем часто в автоматическом режиме. Когда вопрос идет о покупке или продаже ценных бумаг, такой подход можно считать оправданным. Но если речь идет о чем-то большем? Например, прогнозировании действий вероятного противника? Скайнет становится ближе?
Текущие тенденции
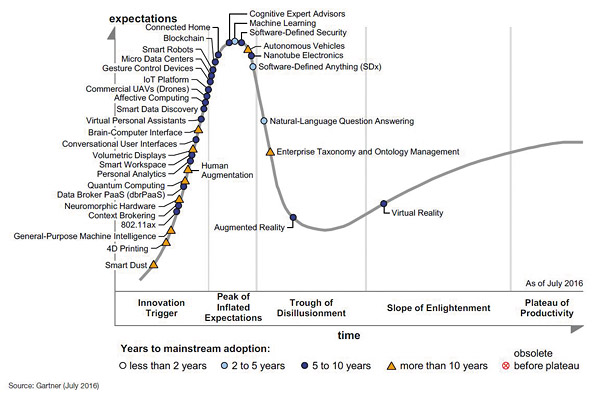
Чтобы понять текущие тенденции обратимся к отчету «Циклы зрелости Gartner 2016: Основные тенденции и новые технологии». Еще в прошлом году Gartner исключила Big Data из числа прорывных технологий (emerging technologies) и удалила ее с графика Hype Cycle, что дало повод некоторым специалистам говорить о «конце Big Data». В реальности ничего страшного не произошло. Зонтик стал слишком большим, и Gartner просто извлекла из-под него технологии и разместила их на кривой отдельно. Это и машинное обучение (Machine Learning), и предиктивная аналитика, и Spark, и исследования на базе Hadoop, и Deep Learning, и озера данных. Естественно, большие данные не появились и на графике этого года.
Процесс дробления продолжился. Из прошлогодних технологий на графике остались лишь машинное обучение, интеллектуальное обнаружение данных (Smart data Discovery), анализ эмоций (Affective computering). Ушла на плато продуктивности предиктивная аналитика, которая уже прочно завоевала свое место в промышленности. Зато появились другие технологии, которые раньше могли бы рассматриваться под зонтичным термином Big Data, а теперь, скорее, под термином «умные машины». Это искусственный интеллект общего назначения (General-Purpose Machine Intelligence), персональная аналитика (Personal Analytics) — cоветы человеку по поддержанию своего здоровья, обеспечения личной безопасности, управления своими финансами. К этим же технологиям относятся «умные» роботы (Smart robots), брокеры данных и даже «умная» пыль (Smart Dust) — распределенная сеть нанороботов, которую тоже можно рассматривать как некий искусственный интеллект.
По-прежнему на кривой остаются технологии, которые можно объединить зонтичным термином «Интернет вещей». Это «подключенный» дом (Connected Home) и переживающие сейчас взлет популярности платформы Интернета вещей (IoT Platforms).
Да, технологии, находящиеся под «зонтиками» IoT, больших данных, ИИ, рождаются, развиваются, выходят на уровень использования в промышленности или умирают. Но сами направления живут и имеют отличные перспективы. А какие еще могут быть перспективы в нашем стремительно развивающемся цифровом обществе?
Масштабы изменений и глубина охвата различных областей жизни и деятельности человека дают основание говорить о новой промышленной революции. Некоторые ее перспективы внушают оптимизм. Некоторые — пугают. Новые технологии, такие как Интернет вещей, облака, большие данные, радикально меняют нашу жизнь. А место молодого аспиранта, ночующего в вычислительном центре, пытаясь разобраться в лавине собранных данных, все уверенней занимает ИИ.