



На сайте MapR-DB появился открытый материал для ознакомления разработчиков (Developer Preview), показывающий как эта NoSQL-СУБД теперь может естественным образом обрабатывать документы в формате JSON. Эта новация призвана упростить и ускорить разработку приложений для работы с большими данными.
Добавление поддержки JSON к проприетарной HBase-совместимой широко-колоночной СУБД будет также способствовать снижению нагрузок по переброске данных внутри и вне Hadoop. Новая функция предоставляет быстрый доступ к документам для аналитики, сообщает фирма MapR, поставляющая дистрибутив Hadoop.
«Поскольку мы можем естественным путем хранить JSON-документы и манипулировать ими в базе данных, пользуясь нашим новым JSON API, это делает разработку очень легкой и быстрой», — заявил технический евангелист MapR Тагдуал Гралл.
«Значит, создание и внедрение новых функций значительно ускоряются. Другой важнейшей стороной дела является факт интеграции с платформой Hadoop. Если вам требуется какая-то сложная обработка данных, какое-то машинное обучение, вам больше не придется перебрасывать данные. Вы сможете использовать ту же самую схему формата, и вам будет не нужно ничего перемещать или развертывать».
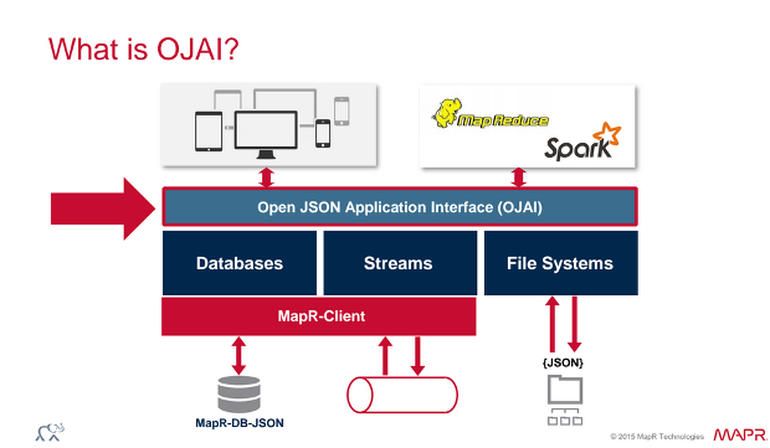
MapR-DB, призванная привнести в Hadoop операционную аналитику, поставляется с Open JSON Application Interface или OJAI, который описывается как универсальный слой доступа к JSON, работающий поверх баз данных, файловых систем и потоков сообщений.
MapR-DB с поддержкой JSON предоставляется бесплатно как часть MapR в версии Community Edition, допускающей продуктивное использование, а ее официальный выпуск намечен на конец текущего квартала. Фирма MapR также продает корпоративную версию этой СУБД с добавочными функциями, в частности, обеспечивающими высокий уровень готовности, аварийное восстановление и репликацию данных.
До того, как была добавлена поддержка JSON, пользователи могли решать проблемы манипулирования документами при помощи иных средств или NoSQL-СУБД. «Но если вы хотите это объединить с машинным обучением — скажем, для обнаружения каких-то мошеннических действий или выдачи каких-то рекомендаций — вам придется перемещать данные из операционной базы данных в платформу больших данных и заниматься их дальнейшей обработкой, а кроме того регулярно все это обновлять», — сказал Гралл.
«Другим вариантом является использование бинарного контента MapR-DB или HBase. Но для разработчиков это очень сложный API. Поэтому поддержка JSON упрощает управление данными и разработку».
Гралл отметил, что использование JSON-документов или log-файлов на базе JSON заметно расширяется, что потенциально ведет к интенсивному переносу данных между системами.
«Причина важности наличия операционной СУБД внутри дистрибутива заключается в том, что тогда вы сможете осуществлять запросы к данным непосредственно в СУБД и соединять их в какой-нибудь конкретной аналитической задаче с другими данными, присутствующими в вашем кластере», — сказал он.
«Опять-таки, вам не потребуется ничего перемещать. Мы активно работаем над интеграцией с нашим SQL-движком, Apache Drill, чтобы аналитику было очень легко подключить это к своим инструментам. Путем интеграции Apache Drill мы хотим предоставить аналитикам возможности обнаружения и другие аналитические функции при наличии любого инструмента, совместимого с SQL».
Материал Developer Preview включает примеры кода, документацию и демонстрацию, а также привязки к языкам Java, Python и Node.js.
Включение в выпущенную в июне MapR-DB 5.0 функций репликации таблиц с многих узлов и наличие возможностей глобального развертывания СУБД тоже получают плюсы в контексте естественной поддержки JSON.
«Если вы работаете в розничной торговле или в сфере здравоохранения и имеете много дата-центров по всему миру или в разных штатах, вам может потребоваться возможность агрегировать данные в одном дата-центре. Например, у вас есть магазины во всех штатах, и вы хотите заниматься аналитикой и трансформацией. Предпринимать что-то дополнительно вам не придется», — сказал Гралл.
«Вы просто организуете репликацию ваших JSON-таблиц в разных штатах в центральную штаб-квартиру. Возможности репликации позволяют вам выбирать, всего лишь посредством нескольких строк конфигурации, конкретные колонки, которые вы хотите или не хотите отправлять в центральный дата-центр. Это очень полезно для агрегации данных».